Home  Image Processing Cluster Analysis Fuzzy c-Means Clustering Image Processing Cluster Analysis Fuzzy c-Means Clustering |
||||||||
See also: Hierarchical Cluster Analysis, k-Means Clustering
 |
||||||||
  |
||||||||
Fuzzy c-Means Clustering |
||||||||
|
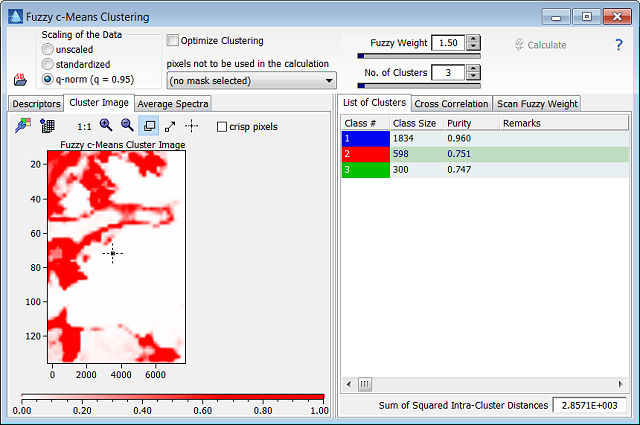
Fuzzy c-means clustering was introduced by Bezdek et al. in 1984. It is an unsupervised algorithm which requires a user-defined number of clusters. The difference to classical k-means clustering is based on the idea of assigning a class membership value to each pixel which reflects the probability of belonging to a particular class. Thus fuzzy c-means delivers class regions which overlap in the image. The cluster analysis is performed using the loaded spectral descriptors, which may be (de)selected on an individual basis by ticking off the corresponding check box in the list of spectral descriptors. The results of the k-means clustering is displayed as a colored map, which can be processed in the usual way (copy to the 2D Imager, copy to the image stack, export to DataLab). Furthermore, a particular class of pixels can be copied into the mask editor, thus enabling the user to exclude these pixels from further calculations. The fuzzy c-means algorithm is prone to unfavorable initial positions of the cluster prototypes. This can be circumvented by repeating the algorithm with different starting positions several times and finally using the set of starting conditions which result in the smallest intra-cluster distance. If you tick off the check box "Optimize", the fuzzy c-means model is calculated 20 times, showing the best of these trials.
|
||||||||
 Image Analysis > Cluster Analysis > Fuzzy c-Means Clustering
Image Analysis > Cluster Analysis > Fuzzy c-Means Clustering